

カイポケ・データプラットフォームチームの河本と申します。以前にSMS Tech blog では 「なぜ介護事業者向け経営支援 SaaS「カイポケ」でデータプラットフォームをこれから作るのか」 では介護を取り巻く社会環境の観点からデータプラットフォームに求められる要件について、「「マーケットに向き合う」エンジニアと経営陣がいたからこそ爆誕したデータプラットフォームチーム」ではデータプラットフォームチームのこれまでの進捗について、社内でのミッション設定やチーム組成について語ってきました。
この記事では、これらの記事に続いて、データプラットフォームのシステム構成と背景にある設計の指針や思想について解説します。
データプラットフォームの価値発揮領域
データプラットフォームの機能を通して実現したい価値は以下のように整理できると考えています。
- プロダクト施策のための主要なプロダクトメトリクスのダッシュボードをつくる
- エンジニア/PdMがデータを障害対応に利用し、円滑かつ安全な復旧対応ができる環境
- (将来的に)顧客とのコミュニケーションのためにアクションを働きかけるいわゆる“Call to Action”を実現する
また、これを実現するためのチームの機能的な要件として以下のような特質についても備えておくことが効果的であると感じています。
- 利用者がデータを信頼して利用し、データプラットフォームチームへの気軽なフィードバックが可能な環境
- 組織内の用語が統一され、高いレベルの共通理解の下で開発に関わるコミュニケーションが取れる環境
データプラットフォームをめぐる制約条件
データプラットフォームの構築にあたり、制約条件として以下のような要素を検討しました。
- 要配慮個人情報を取り扱っていること
- ドメインの性質上、取り扱いに慎重な配慮を要する個人情報を含んだデータベースを扱う
- システムが複数のサービス・コンポーネントに分割されていること
- カイポケリニューアルプロジェクトではマイクロサービスアーキテクチャを採用しており、フロントエンド、バックエンド共に複数のサービス・コンポーネントに分割されている
- 社内のルールが規定されていない新しい領域を開拓していること
- データプラットフォームチーム自身が情報セキュリティや運用ルールなどに対して自ら提案、発信していくことも求められる
- 法律に定義された業務を支援するSaaS特有の複雑性
- 関連法規の改正に伴い、頻繁に変更されるシステムにデータとその活用が追従しなければならない
データプラットフォームのシステム要件
セキュリティ
カイポケのデータベースに格納されている情報には要配慮個人情報を含まれています。データプラットフォームには、現時点では直接エンドユーザ様が利用したり、影響を受けるサービスを提供する予定は無いですが、チーム運営に欠かせないコンポーネントとして一定以上に高い可用性を持つ必要があります。
長期間にわたって多くの利用者に安全に、安定して利用できることを目指しているデータプラットフォームにおいて情報セキュリティの三要素である「可用性」「機密性」「完全性」はいずれも重要な性質です。
以下に説明していくシステム構成には、例えば以下のようにこれらの考慮が反映されています。
可用性
現在は非常に小規模なチームで構築・運用を行っているデータプラットフォームチームの制約上、高い可用性をコストパフォーマンスよく実現するため、マネージドサービスも適宜活用して運用負担の軽減を図っています。
機密性 (PIIについて)
カイポケはサービスの性質上、要配慮個人情報(個人の健康・医療情報など管理上特別な配慮を要する情報)を保有しており、これらの情報が安全に管理されることを担保する必要があります。
データプラットフォームでは要配慮個人情報に対する保護策として、BigQueryでの列レベルのアクセス制御もしくはViewへのアクセス制御などを通じて、権限設定のレイヤーで安全性を担保する予定です。
システム構成
データプラットフォームが構築するシステムの構成は以下の構成の通りとなっています。現在も構築の過程にあるので、今後もある程度は変動する可能性があります。
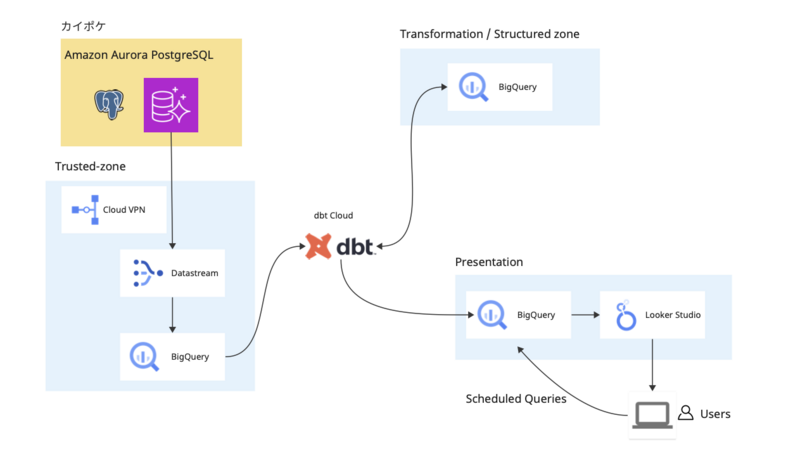
カイポケではクラウドプラットフォームとしてAWSを利用していますが、データプラットフォームではGoogle Cloud Platform(以下GCP)を採用しています。選定に当たってはチーム内で様々な観点(コスト、セキュリティ、パフォーマンス、運用経験者の採用の容易さなど)から比較検討を行い、BigQueryを中心とするGCPのプロダクト群を中心に設計することに決めました。
全体構成
システム全体は3層の構成をとっています。3層構成にした意図は安全性と柔軟性を高いレベルで保つためであり、以下のそれぞれの層についての解説を読んでいただくことでその具体的な設計意図が理解いただけると思います。
セキュリティに関する前提として、インフラの構成変更に関する作業は全てIaC(Terraform)のCI/CDを通して行われ、意図した変更のみが実行されることを担保しています。
1層目 - landing層
1層目のlanding層ではカイポケのデータソース (* 現在のところスコープはRDSに限定) のコピーを保有し、BigQueryに保存します。この層でのBigQueryはデータベースの保有している情報を全てコピーすることに徹しており、原則として加工されていません。
データベースへのコピーはGCPのDatastreamサービスを使ってAWSで構築されているカイポケのデータベースの論理レプリケーションでBigQueryへの転送を実現しています。
この層のアクセス権限はデータの内容に踏み込まず、単純なコピーを行ったデータが保存されており、要配慮個人情報も格納されているためデータに直接アクセスできる権限は厳密に業務上必要最小限の範囲に限定する必要があります。
2層目 - transformation層
2層目のtransformation層では、1層目に転記されたBigQueryのデータをdbt Cloud を用いて書き換え、データマートを形成するための層です。
複雑なドメインである介護事業者向けSaaSのデータベースの生のデータは、ビジネスメトリクスの間にはデータセマンティクスのギャップが大きいです。そのままでは細かいレベルのドメイン知識がなければデータを扱いにくいため、この層でビジネスメトリクスに落とし込むための意味的な変換も行っています。
3層目 - presentation層
3層目のpresentation層では、ビジネスKPIの状況をダッシュボードで確認するための層です。現時点ではLooker Studioを利用することを想定しています。プロジェクトの進行に伴い、必要に応じてTableauや Lookerなどを比較検討することも考えています。
まとめ: 現在取り組んでいること
データプラットフォーム構築のインフラ基盤と分析パイプラインの構築は現在「ワンパス通っている」状態(完成度を問わなければ必要最低限の業務の流れが全て流せる状態)に到達しています。今後もデータプラットフォーム内のサブプロジェクトとして「プロダクトメトリクスダッシュボード」「信頼されるデータ環境づくり」「開発者の調査に使えるデータ環境づくり」「ユビキタス言語の開発」「クライアントログの整備」など、各方面から信頼される高品質なデータプラットフォームに到達するまでにやりたいことがたくさん積んである状態です。
データプラットフォームチームは副業メンバーの構成比率が高く、カイポケ開発とは密接に連携しながらも独立した別のシステムを構築したり、関係部署と独自の連携をとったりなど多様な業務を少人数で行っているという意味で、やや変わった特徴のあるチームとも言えそうです。システム開発の経験はもちろんとても役に立てることができますが、システム開発そのものにどっぷり専念するよりももっと多様な活動をしてみたいというエンジニアの皆様には興味を持っていただけると思います。
この記事を最後まで読んだ読者の方の中で、こうしたデータプラットフォームの開発に興味を持った方がいらっしゃれば、ぜひカジュアルにお話しできればありがたいです。