

はじめに
医療・介護・ヘルスケア・シニアライフの4つの領域で高齢社会の情報インフラを構築している株式会社エス・エム・エスのAnalytics&Innovation推進部( 以下、A&I推進部)でデータ分析基盤開発を担当している長谷川です。
A&I推進部はエス・エム・エス社内のデータを横断的に収集し、データの分析や加工から、データに基づく施策までを行う部門で、現在は介護事業者向け経営支援サービスである「カイポケ」や、介護職向け求人情報サービスである「カイゴジョブ」のデータ分析やレコメンドシステムの開発を行っています。
今回はその中で「カイゴジョブ」における介護求人の課題をディープラーニングによる分類モデルで改善した取り組みについて紹介します。
介護業界の課題
具体的な説明に入る前に、簡単に介護求人の課題感を説明します。
ご存じの通り、昨今の日本は少子高齢化が進み、介護にまつわる課題が毎日のように新聞やテレビなどで取りざたされていることと思います。
介護業界に関する課題は多くありますが、介護の需要が増大する一方で生産年齢人口減少によりサービスを支える介護従事者の不足が大きな問題となっています。
こちらは公益財団法人介護労働安定センターの調査結果ですが、介護職員全体の不足感は65%以上と高く、また様々な理由により介護従事者の採用が困難になっています。

このような課題を解決すべく、エス・エム・エスでは介護職向け人材紹介サービスであるカイゴジョブエージェントや、介護従事者向け求人情報サービスカイゴジョブ 、介護・医療・福祉の資格講座情報サービスシカトルなどの介護・医療・福祉の資格講座情報サービスを通じて「医療・介護の人手不足と偏在の解消」に貢献を目指しています。
A&I推進部の取り組み
A&I推進部は、数理技術や先端技術を用いたデータ活用を通じたイノベーションによるエス・エム・エスの事業課題解決を通じた業界への貢献をミッションとした横断組織です。
A&I推進部の業務はデータ分析からシステム開発、共同研究など多岐に渡りますが、今回はその中でもカイゴジョブの開発を担当するプロダクト開発部と協力して進めている施策について紹介します。
介護求人における課題
カイゴジョブは多くの介護求人を扱う検索求人サービスですが、それらの情報を求職者の望む形でどのように届けるか、求職者に寄り添ったうえでどのようなサービスを提供するかについて日々研究・改善を進めています。
求人票の情報の多くはカテゴリ化されたセグメントデータの他に、多くのテキストデータも入力されます。特に介護保険制度は2000年4月に施行された比較的若い制度のため、およそ3年ごとに大きな見直しが入り資格や用語などが変遷してきたという背景があり、その影響で入力されるテキストデータにもかなりの幅があります。
例えば「介護福祉士」は介護職で唯一の国家資格ですが、介護福祉士の受験資格として「介護福祉士実務者研修」があり、これは2013年以前は「ホームヘルパー1級」と呼ばれていました。
そのため「介護福祉士実務者研修」を有する従事者を求める求人票には「介護士」や「実務者(研修)」「ホームヘルパー1級」「ヘルパー1級」「旧ヘルパー1級」などの記載が現在でも多く使われています。
また資格としては「介護職員初任者研修」から「介護福祉士実務者研修」へ、さらに国家資格である「介護福祉士」へと続くため、「介護職員初任者研修以上」と書かれる求人票も多く、この場合は「介護職員初任者研修」「介護福祉士実務者研修」「介護福祉士」いずれかの資格を有する従事者を求めていることになります。
このように介護における応募資格は複雑に入り組んでおり、具体例を挙げるとこのような表記をされることが多いです。
・初任者研修(ヘルパー2級)以上
・ヘルパー2級(介護職員初任者研修修了者) ・介護福祉士 ※いずれか必須
・ヘルパー1級、基礎研修、介護福祉士のいずれか
【いずれか必須】 ■介護福祉士 ■介護職員実務者研修(旧ヘルパー1級)
【いずれも必須】 ・ヘルパー2級(介護職員初任者研修修了者)以上 ・普通自動車免許(AT限定可) 【あれば尚可】 ・介護福祉士(優遇)
このようなテキストデータから、介護事業所の求める資格情報を抽出し、レコメンドなどに利用する場合、正確性を担保しつつも様々な表現に柔軟に対応できるロジックが必要となり、A&I推進部ではこの課題に対して最初に正規表現を用いた抽出ロジックを検討しました。
正規表現による抽出
正規表現は法則化された文字列の一致を検出するケースにおいて正確に対象を抽出できますが、求人票のような意味合いは似ているが表現が複数あるようなテキストの抽出を行うには、例外となるケースが多すぎ、それらを全て拾うことが困難であることが分かりました。
例えば【いずれか必須】と【いずれも必須】では意味合いが変わりますし、歓迎資格でも【次の資格・経験お持ちの方は尚可】と【上記あれば尚可】では求人票のどの部分を指しているかが変わるため、正規表現による抽出は断念し、代わりにニューラルネットワークを使った分類モデルの開発に着手しました。
応募資格構造化モデル
A&I推進部で開発に着手したモデルは、求人票の応募資格を入力データとし、あらかじめ決められたカテゴリ構造に属するか否かを推論するモデルですので、名称を応募資格構造化モデルとしました。
モデル選定の選定については、入力テキストを時系列と見立て、文章の前後関係を学習するLSTMやTransformer、大規模な事前学習タスクを学習することで汎用性を獲得したBERTがありますが、求人票の応募資格は記述に極端な乖離がなく、介護という専門領域では比較的専門的な用語が頻出することから、事前学習モデルは利用せず、LSTMとAttentionをベースとした独自モデルとしました。
LSTMはディープラーニングの中でも時系列データを扱うリカレントニューラルネットワークの一種で、RNNよりも長期的な依存関係を学習します。
さらにAttentionという、結果に対してどの単語が影響するか注意して学習させる機構を追加することで精度向上が期待できます。
カイゴジョブは介護領域の求人の中でも多くの職種を掲載しておりますので、構造化のカテゴリ数も多く、応募資格構造化モデルでは108種類の構造化を対象としました。
以下はその一例です。

開発当初は1つのモデルで108種類の構造化を行うように設計していましたが、カテゴリによっては訓練データに偏りがあり、また学習時間もかかるなどの問題があったためカテゴリをグループ単位に分割し、4つのモデルを並行で訓練することとしました。
LSTMモデルはテキストを時系列データとして扱うのですが、テキストをそのまま学習することはできず、文字列を単語単位に分割する必要があります。 テキストを単語単位に分割する場合、日本語は英語のように単語の区切りが自明ではないため、文字列を1単語ずつ区切るか、形態素解析器を利用して形態素という単位に分割する必要があります。
例えば「いずれか必須」という文字列があった場合、1単語ずつ区切ると「い」「ず」「れ」「か」「必」「須」の6単語になりますが、MeCabという形態素解析器を利用する場合は「いずれ」「か」「必須」の3つの形態素に分割されます。
応募資格構造化モデルでは求人票の文脈を理解させたかったので形態素解析器を利用した単語分割としました。
またその際、通常のMeCabでは「介護福祉士」は「介護」「福祉」「士」まで分割されてしまいますが、このモデルでは「介護福祉士」を1単語として扱いたかったため、必要な資格は予めMeCabのユーザー辞書に登録しました。
こういった固有表現に強い辞書としてmecab-ipadic-NEologdがあるのですが、介護の資格である「初任者研修」を正しく分割しないなどの問題があったため、今回は標準辞書にユーザー辞書を足す形で文字列を分割しました。
訓練はGCPのVertex AIを利用し、ai-platformでジョブ登録することで不要なインスタンスが起動し続ける状態を回避するとともに、インプットの訓練データを変数化し同一ソースで複数のモデル学習を並列で実行しています。
gcloud ai-platform jobs submit training $JOB_NAME \
--module-name $MODULE_NAME \
--package-path ./packages \
--runtime-version $RUNTIME_VERSION \
--region $REGION \
--job-dir $OUTPUT_PATH \
--python-version $PYTHON_VERSION \
--scale-tier BASIC \
-- \
--batch-size $BATCH_SIZE \
--epochs $EPOCH \
--train $INPUT_PATH \
...
モデルの詳細
応募資格構造化モデルの訓練手順を以下に示します。
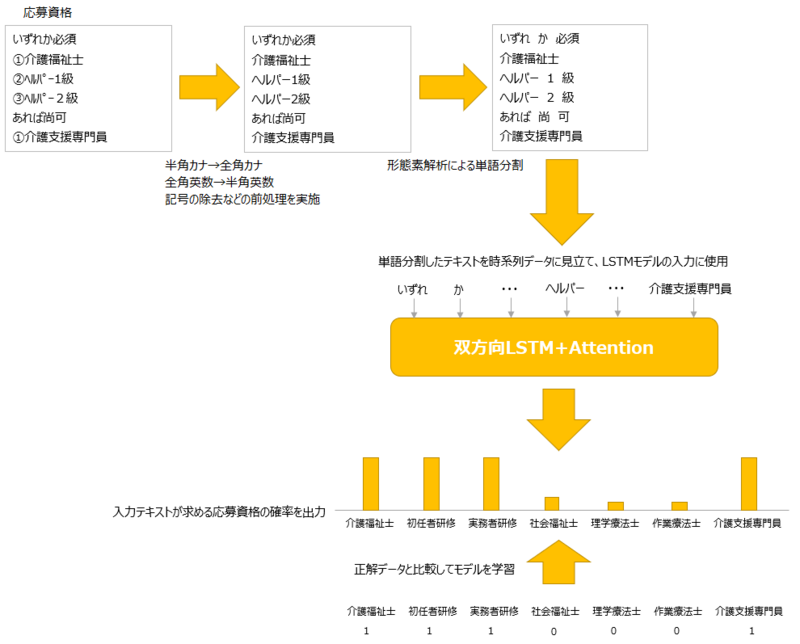
- 最初に応募資格テキストの半角文字を全角に変換、記号を除去するなどの前処理を施します。
- そのうえで1.の応募資格をMeCabを使い単語単位に分割します。
- 2.で分割した単語の並びを入力として双方向LSTM+Attentionモデルを通し、各応募資格ごとの確率を出力します。
- 3.の結果を正解データと比較し、正解との誤差を算出します。
- その誤差を最も少なくするために学習を繰り返します。
1~5を繰り返し、誤差が少なくなった時点で訓練を終了します。
モデルの精度と改善の仕組み
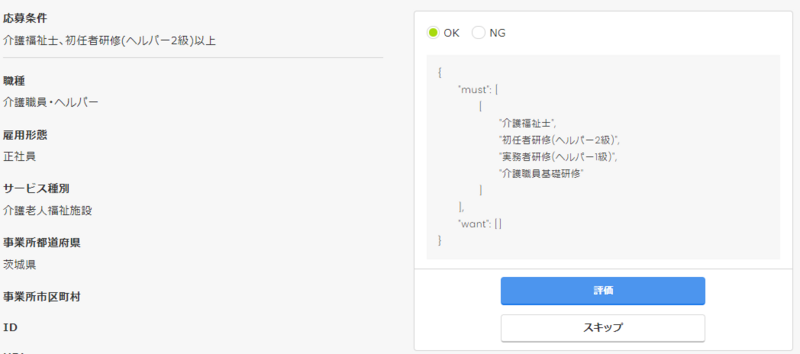
約9,000件のデータを用いて訓練を行い、500件のテストデータで評価した結果、99.5%の精度となりましたが、実際の求人票で推論すると成果率は約80%くらいまで落ちてしまいます。
カイゴジョブには誤った推論データをアノテーションできる専用画面が作られており、この画面を通じて入力した訂正結果を訓練データに追加して再訓練することで精度向上を図っています。
データ連携
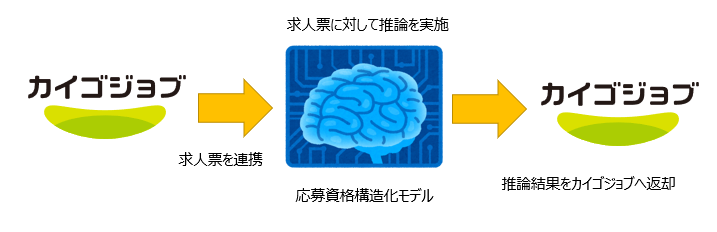
応募資格構造化モデルはA&I推進部で開発・訓練を行います。
そのためカイゴジョブのサービスとは切り離されており、データの連携は日次バッチで行っています。
求人票をデイリーでA&I推進部の環境へ連携してもらうと、A&I推進部ではその中身を確認し、前日との差分のみを取り出したうえで応募資格構造化モデルで推論を行い、結果をカイゴジョブに戻す形でデータを連携しています。
モデルの活用
カイゴジョブでは利用者の希望条件にマッチした求人情報をメールマガジンという形で定期的にお届けしています。
求職者に入力いただいた希望条件と、求人票の内容をマッチングしたうえで求人票をお送りしていますが、その際に求人票から応募資格構造化モデルで推論した条件を利用してメールをお送りしています。
応募資格によってはほぼ100%の精度となるものや、改善が必要な資格もあり、一定の精度以上の資格のみメルマガで活用し、そうでないものは、モデルを改修して引き続き精度の向上を進めています。
さいごに
エス・エム・エスには数多くのサービスがあり、特に介護、医療に特化したデータを数多く保有しています。データサイエンスを活用したサービス向上ニーズも高く、今回の記事で少しでも興味を持って頂ける方がいらっしゃいましたら是非お話を聞きに来ていただけたらと思います。