

この記事は 株式会社エス・エム・エス Advent Calendar 2023 の11日目の記事です。
無いに越した事はありませんが、サービスを長い間運用しているとどうしてもシステム障害対応をやらなければいけないタイミングがあります。この記事では、小規模なアラート対応から数日間に渡るチーム横断での大規模障害までいくつのシステム障害対応に関わる中で実際に私が行ってきた事を 11 個紹介してみようと思います。
前置きとして、現在私が所属するチームはほぼ100%フルリモートで開発を行っており、それを前提とした内容になっています。
- 1. 専用のコミュニケーションスペースを作る
- 2. 役割分担をする
- 3. 積極的に音声通話でやりとりする
- 4. 情報整理用のダッシュボードを作る
- 5. 専用のカンバンを作る
- 6. 情報同期のための定時ミーティングを設ける
- 7. 通常業務を進めるメンバーを残す
- 8. メトリクスのスナップショットを残しておく
- 9. 異なるメトリクスを同じ時系列で並べる
- 10. 他のチームにも相談してみる
- 11. 意識して休憩を取る
- 最後に
- 関連資料
1. 専用のコミュニケーションスペースを作る

まず、障害対応モードに入ったほうが良いと判断したタイミングで誰でも良いので専用の Slack チャンネルを作ります。これにより障害対応の情報を一つのチャンネルに集約して、普段チームが利用しているチャンネル上で障害対応の情報がノイズとならない様にします。関連する情報へのリンクは slack チャンネルの関連ページや canvas に記載しておきチャンネルから辿れる様にしておくと便利です。
その後、チャンネルを作ったらすぐにチャンネル上で huddle を立ち上げて関係者を呼び寄せ、障害対応の情報収集や役割分担を行います。
2. 役割分担をする
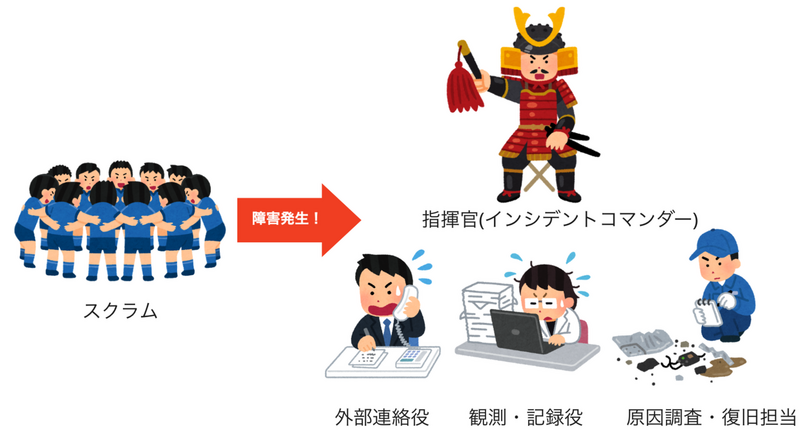
意思決定を迅速に行うために、インシデントコマンダーを頂上とした階層構造の組織体制を作ります。
- 指揮官(インシデントコマンダー) -- 全体の指揮を取り、他の役割を動かすための意思決定を行う
- 外部連絡役 -- カスタマーサポートやリスクマネジメントの部署とやりとりをし、チーム外とのコミュニケーション窓口となってもらう。普段からそういった部署とやりとりをしてもらっているメンバーに担当してもらう場合が多い。
- 観測・記録役 -- 原因調査・復旧担当や外部連絡役から入ってくる情報をまとめて、皆に伝えやすい形にする。インシデントコマンダーである自身が兼任する場合も多い。
- 原因調査・復旧担当 -- サーバーのログやメトリクスの調査を行い原因調査を行う。ほとんどの場合技術者が担当する。
場合によってはこれら以外にも現象の再現を試してもらう役割を作るなど臨機応変に対応します。いずれの役割を決める際も、コミュニケーションが混線してしまわない様に役割に対してまとめ役を必ず1名任命して、基本的にインシデントコマンダーはそのまとめ役とコミュニケーションを行う様にします。
なお、私の所属するチームはスクラムチームとして活動しているため通常時はトップダウンで意思決定を行う事はほぼありませんが、障害対応の際は例外的にこの様な体制に切り替えています。
3. 積極的に音声通話でやりとりする
障害対応では不確定な判断材料でリリース内容のロールバック、サービス停止、サーバースペック増強等の難しい判断を迅速に行う必要があります。このためコミュニケーション速度が速く、微妙なニュアンスを把握しやすい音声通話でのやりとりを積極的に使って作業を行います。特に対応初期はメンバーが揃わず情報収集もしづらいため、しばらく huddle を立ち上げっぱなしにしておいて状況の変化があった際にすぐに報告したり、何かを確認する際に声をかけやすい状況を作ります。
注意点としては、あまり多くの参加者が障害対応の本部機能を持った音声通話に入ってしまうと本部機能のノイズとなってしまう事があるため、役割分担が済み原因調査が動き始めたタイミングでそれぞれの役割ごとに音声通話を分けてもらう様気をつけています。
4. 情報整理用のダッシュボードを作る
障害対応時の情報整理は Notion 等のドキュメント管理ツールより miro の様なオンラインホワイトボードをダッシュボードとして使う様にしています。
ドキュメント管理ツールはシーケンシャルに構造化された情報を扱うのには向いていますが、複雑な関連性を表す表現力はありません。
オンラインホワイトボードツールであれば位置関係が離れている情報もドラッグアンドドロップですぐに移動できますし、何より縦横の二次元で情報を表現できます。更に位置関係を変えずに線を引いたり要素を囲ったりしてあげることで柔軟に情報の関連性や構造を表す事も可能です。複雑な判断要素が絡む障害対応ではこういった点が情報整理にとても役に立ちます。
5. 専用のカンバンを作る

状況が混乱していると記憶や認識のずれが発生しやすくタスク状態があやふやになる場合が多いです。これを避けるために障害対応専用のカンバンを作ります。私は miro の カンバン 機能を使い、標準のカラムに Backlog というカラムを追加して
Backlog(検討中のもの)To do(実施が決ったもの)In Progress(対応中)Done(完了)
というカラムがある状態にしています。今後進めるタスクの提案はいったん Backlog に入れて、対応する事が決まったものは To do へ、実際に実施中のものは In Progress へ移動して、状況が変わったら Done へ移動したり Backlog に戻したりといった運用です。
miro のカンバンは担当者を設定したり期日を決めたりすることも可能ですし、ホワイトボード上の他の情報から矢印を引っ張って関連付けを行う事ができるため GitHub Projects や Jira 等のカンバン専用のツールよりも柔軟な使い方ができます。障害対応では、この様にラフに使えるタスク管理方法のほうが情報を整理しやすいです。
6. 情報同期のための定時ミーティングを設ける

状況に応じてだいたい1〜2時間ごとに情報同期のための定時ミーティングを設けます。このミーティングでは
- 現在の状況に合わせてカンバンのアップデート
- 新たに発見した情報の共有
- 次に実施・中止するタスクの選定と担当決め
を行っています。このミーティングは不確定要素の多い状況への適応とその対応を行うためのリズムを作ることを目的として、スクラムのデイリースクラムとプランニングをとても短い間隔で行うイメージでやっています。
7. 通常業務を進めるメンバーを残す

障害が発生すると不安から「全員で障害対応を行おう!」という気持ちになってしまう事があります。しかし、障害の内容によってはその原因調査を行えるメンバーが限られていたり、障害対応以上に重要な通常業務が存在する場合もあります。必要以上に障害対応への人員投下をするのでは無く、障害対応に入ってもらう必要があるメンバーを明確にしたうえで「〇〇さんは通常業務をお願いします」と、障害対応に入らなくて良いメンバーが明確になる様にしています。
8. メトリクスのスナップショットを残しておく

メトリクスも種類によって保存期間や時間経過で情報の粒度が粗くなってしまい、障害発生当時のメトリクスが後から再現できなくなってしまう事があります。これを避けるために、気がついたタイミングで必ずメトリクスのスナップショットをスクリーンショットで残し miro に貼り付けておく様にしています。この際グラフがなるべく細かい単位で描画される様にしておくのもポイントです。
9. 異なるメトリクスを同じ時系列で並べる
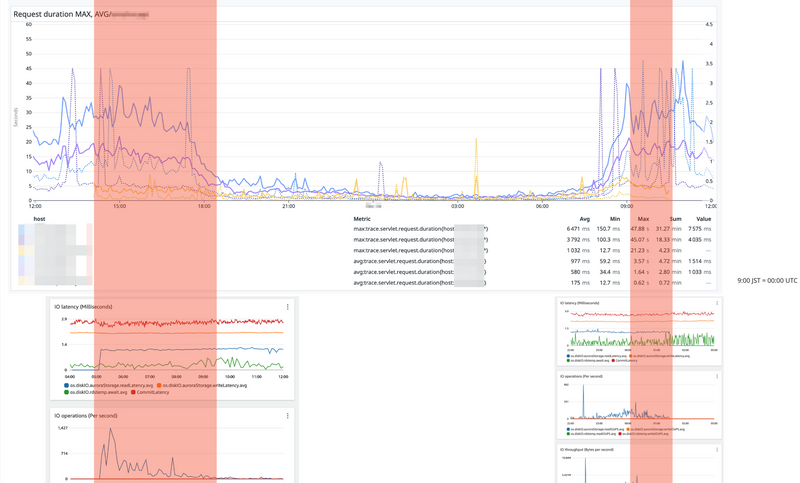
障害発生時の状況把握を行う際はサーバー負荷やエラーレート、お問い合わせ発生日時等といった様々な情報の関係性を把握する必要があります。これを行うには同一時系列上に並列で異なるプラットフォームで取得したメトリクスを並べるのが効果的です。 ここで活用できるのが 8 で残しておいたスクリーンショットです。miro 上でx軸の時間を他のスクリーンショットのx軸の位置と合わせることで AWS 上のメトリクスや Datadog, Google Analytics といったプラットフォームの垣根を超えて同じタイミングで同時に変化が起こっているという状況が把握しやすくなります。miro であればグラフ上の気になる部分に注釈を付けたりする事も簡単にできますし、複数のスクリーンショットを繋げる事でブラウザ上では描画が難しい、長時間に渡るグラフを表現する事も可能です。
10. 他のチームにも相談してみる

障害対応にあたっているチームで原因や対策方法が見つからず解決が難しいと感じた場合、他のチームにも何か気がついた点が無いか相談してみます。複数のサブシステムが一つの共有リソースを使っている様なサービスの場合、特定のサブシステムでのみ発生していると考えられていた問題が実は別のサブシステムの影響によって発生していたり、共有リソースの問題がたまたまそのサブシステムに影響を与えていたという事もあり得ますし、他のチームメンバーが持っている専門知識によって意外な解決策が見つかる可能性もあります。
緊急事態なので、頼れる物は貪欲に頼るのが吉です。
11. 意識して休憩を取る

障害対応は場合によっては深夜作業や休日作業が発生してしまい体力的にハードなものです。この状態が続いてしまうと判断力が低下し、通常業務では行わない作業をやっている事も相まって不適切な情報を共有してしまったり、オペレーションミスでデータを削除してしまったりといった二次災害1を招いてしまう事があります。これを避けるために、意識して休憩を入れる様にします。
打ち合わせや議論が長くなる様であれば1時間ごとに小休憩を挟み、できるだけ昼休憩は通常と同じ様に設け、日が変わる前に一旦その日の対応を終え翌日再開できる様な動きができると理想です。当然それが難しい状況もあるのですが、その場合はシフトを組むなどして負荷が集中してしまわない様に配慮します。
最後に
この記事を書くために当時の slack チャンネルを見ていると大変だった記憶が蘇ってきました。システム開発に関わる皆さんが、年末年始は何も起きず無事な年越しができる事を祈っています。
最後に、私が障害対応をするにあたって参考にしている資料を記載しておきます。
(筆者: プロダクト開発部桐生)
関連資料
- 今日からできる。初めての障害対応ガイド | DevelopersIO (dev.classmethod.jp)
- インシデント指揮官トレーニングの手引き | Yakst (yakst.com)
- Google - Site Reliability Engineering (sre.google)
- 重大事故の時にどうするか?|miyasaka (note.com) -- ヤフー株式会社(現LINEヤフー株式会社)の元社長宮坂さんによる記事。
- (PDF) National Incident Management System - Incident Command System (ICS) | FEMA.gov (www.fema.gov) -- アメリカ合衆国連邦緊急事態管理庁の資料。 Google SRE の資料中でもこのシステムが参照されており、インシデントコマンダーという役割を理解する際に
Incident Command System (ICS)の章を翻訳しながら読みました。
- 疲労が原因によるものでは無いですが、ちょうど最近クラスメソッドさんでもクライアントのインシデント対応にあたって実施した作業でオペレーションミスによる障害が発生していました。 2023年12月5日に発生した複数AWSアカウントが操作不能となった障害について | クラスメソッド株式会社 (classmethod.jp)↩