

この記事は株式会社エス・エム・エスAdvent Calendar 2025 12月3日の記事です。
介護/障害福祉事業者向け経営支援サービス「カイポケ」のソフトウェア開発者の空中清高(@soranakk) です。
本記事ではカイポケのバックエンド開発で取り入れている、スキーマからのコード生成に焦点を当てて取り組みや工夫を紹介したいと思います。
カイポケのシステム概要
まずはこちらの図をご覧ください。
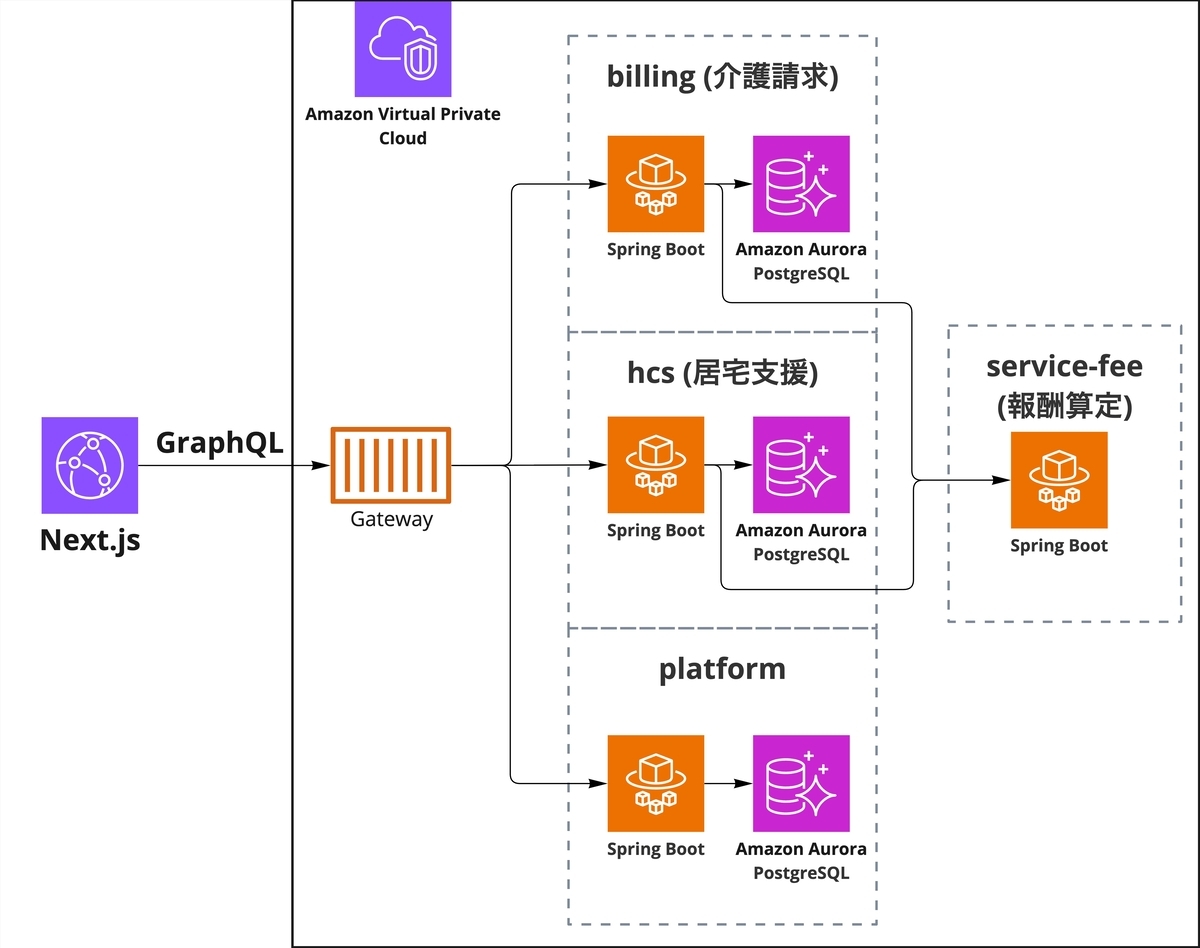
こちらはカイポケのシステム概要図となっています。
バックエンドにはいくつかのサーバーが存在していて、それぞれのサーバーはGraphQL APIを公開しています。
そして、それらをGatewayで1つのGraphQL APIにまとめて、フロントエンドに公開しています。
またそれぞれのバックエンドはSpring Bootで構成されていて、KotlinとSpring for GraphQLを利用して開発しています。
さらにそれぞれのバックエンド毎にデータストアとしてPostgreSQLのデータベースを持っている構成になっています。
本記事ではこれらのバックエンド開発のコード生成に焦点を当てて紹介したいと思います。
コード生成を利用している箇所
コード生成は主に2箇所で利用していて、1つ目はGraphQL Schemaからのコード生成です。
それぞれのバックエンドで公開しているGraphQL SchemaからKotlinのコードを生成して利用しています。
もう1つはデータベースアクセスでPostgreSQLのスキーマからKotlinのコードを生成して利用しています。
GraphQL Schema からのコード生成
カイポケのバックエンドではSpring for GraphQLを利用してGraphQL APIの開発をしているのですが、Spring for GraphQLにはコード生成の機能が存在しません。
そのため、カイポケではDGS Framework (Domain Graph Service)というライブラリのコード生成を利用しています。
DGS frameworkはNetflixが提供している、Spring BootでGraphQLを開発するためのライブラリです。
リンク:https://netflix.github.io/dgs/
DGS frameworkにはコード生成のためGradleプラグインが用意されていて、それを使うとKotlinのコードを生成することができます。
ちなみにSpring for GraphQLの開発においてコード生成でDGS frameworkを利用することは公式ドキュメントでも触れられていますので、半分ぐらい公式的な方法です。
リンク:https://docs.spring.io/spring-graphql/reference/codegen.html
データベーススキーマからのコード生成
カイポケのバックエンドではjOOQというORMを利用してデータベースアクセス層の開発をしています。
jOOQにはデータベーススキーマからのコード生成プラグインが提供されているので、それを利用しています。
jOOQを使ったデータベースアクセスは、例えばソースコードはこのような感じになります。
by公式ドキュメント:https://www.jooq.org/doc/3.20/manual/sql-building/dsl-api/
val result: Result<Record?> = create.select() .from(AUTHOR) .join(BOOK).on(AUTHOR.ID.eq(BOOK.AUTHOR_ID)) .where(AUTHOR.YEAR_OF_BIRTH.gt(1920)) .and(AUTHOR.FIRST_NAME.eq("Paulo")) .orderBy(BOOK.TITLE) .fetch()
この時に利用するテーブル名やカラム名、View名やRecord型などがjOOQによって生成されたコードとなっています。
生成するときはデータベースのスキーマを直接参照して生成することになるので、DockerなどでPostgreSQLを起動しておいたり、 TestContainersを使ったりしてPostgreSQLを起動した状態でコード生成します。
コード生成のメリット:GraphQL
GraphQLのコード生成によってリクエストやレスポンス型のdata classを自分で書く必要がなくなります。
これらはGraphQL Schemaに合わせて定型的な型を定義して利用するだけなので、コード生成できると楽です。
さらにGraphQL Schemaからコード生成されるため、GraphQL Schemaを修正すれば自動的にコードへ反映されるようになります。
そのためGraphQL Schemaを更新したけどコードへ反映が漏れていた、みたいなことにコンパイルエラーで気づくことができます。
ユニットテストやCIでも気づくことはできるのですが、やはり修正してすぐに手元のエディタで気づけるほうが開発者体験として良いです。
コード生成のメリット:データベース
データベースのスキーマは何らかのマイグレーションツールを使って管理していると思います。
カイポケではgolang migrateというGo言語で作られたマイグレーションツールを利用しています。
リンク:https://github.com/golang-migrate/migrate
こちらのツールではデータベースの更新をSQLファイルを使って管理します。
そのためデータベースのスキーマを管理するSQLとアプリケーションコードのKotlinで変更を同期しておかないと、データベースは更新したのにアプリケーションが発行するSQLは古いままでエラーになってしまう、みたいなことが発生しがちです。
そこでデータベーススキーマからコード生成することで、自動的に同期できるようになります。
なのでGraphQLの時と同じく、データベースを更新したけどコードが古いままになっていた、みたいなことにコンパイルエラーで気づくことができます。
CI での活用
スキーマとコードのズレにコンパイルエラーで気づける、という話をしましたがそれでも漏れてしまうこともあります。
そこでGraphQL SchemaやデータベースのマイグレーションのSQLが追加された時などをトリガーにしてCIでコードの自動生成を行なって、変更がコードに反映されているかどうかをチェックしています。
手元で修正漏れがあったとしてもPRのCIでチェックされるので、整合性が取れていない場合はマージされることもありません。
このような自動化が行えることも自動生成の利点だと思います。
まとめ
本記事ではカイポケのバックエンド開発で取り入れているコード生成に焦点を当てて紹介しました。
コード生成を活用することで外向けのインターフェースと内部のソースコードの整合性のチェックが自動化できたり、開発者がコンパイルエラーで不整合に気づけるというメリットがあります。
DGSのようにコード生成部分だけ利用するってケースもありかなって思っています。
また、本記事の内容はKotlin Fest 2025やJJUG CCC 2025 Fallのカンファレンスのエス・エム・エスのブースでも紹介していました。
ブースでは実際のソースコードも見せながら色んな工夫を話すことが出来たので、今後もエス・エム・エスのブースを見かけたら立ち寄ってもらえると嬉しいです。