

はじめに
エス・エム・エス BPR推進部カスタマーデータGrで、「ナース人材バンク」等のキャリア事業を中心に、社内のデータ活用の推進、データ基盤の開発を担当しています、橘と申します。 私達カスタマーデータGrでは、Google CloudのBigQueryを中心としたデータ基盤を構築しており、社員がデータを利用して意思決定をする業務をサポートする役割を担っています。本記事ではそのデータ基盤についてご紹介したいと思います。
カスタマーデータGrのデータ基盤について
私達が運用するデータ基盤のデータ連携アーキテクチャについて、簡単にまとめると以下の図のようになります。
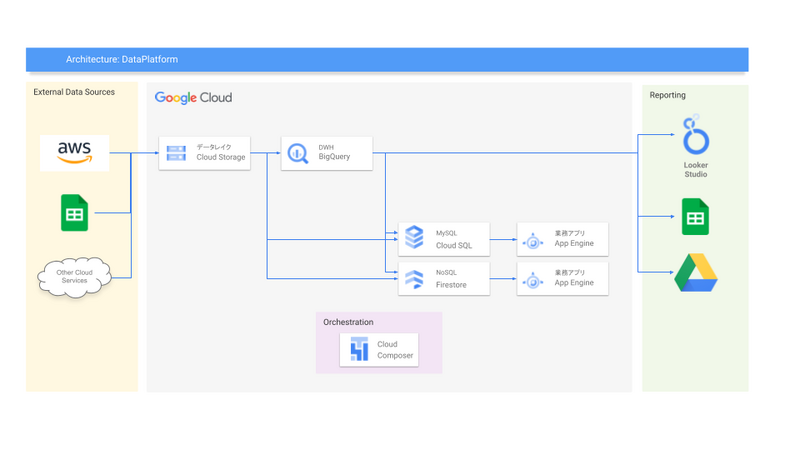
エス・エム・エスのキャリア事業で活用したいデータは、AWS上に構築されたシステム、Salesforce、GoogleドライブやGoogleスプレッドシート、その他SaaS等、様々な場所に散らばっております。これらをGoogle Cloud上のストレージに収集し、利用目的に応じたデータストアへ連携し、業務への活用をする、といった構成となっています。
データ基盤のワークフローエンジン
これらのデータを連携する基盤として、GCP上でApache Airflowをマネージドで提供するサービス、Cloud Composerを利用しています。Airflowでは次の図のようなワークフローをPythonで定義して運用することができます。各処理を動かすタスクを整理し、それを有向非巡回グラフで依存関係を定義し、前のデータのロードが終わったら、そのデータを加工するタスクを動かす、といったことが実現できます。
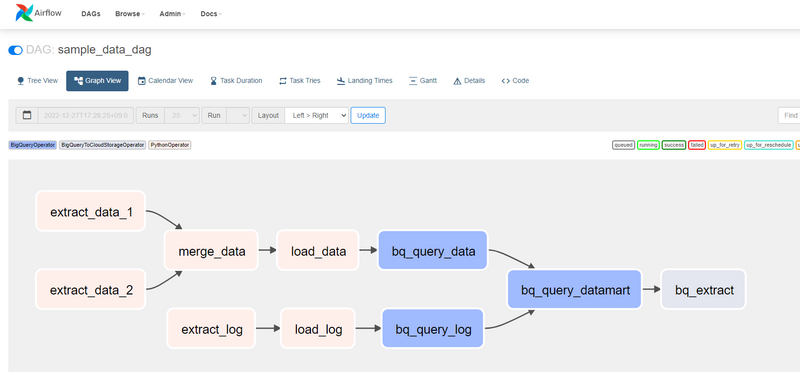
Airflowには、BigQueryやCloud Storage等のGoogle Cloud上の各サービスへ接続する機能が元々あります。その他の外部サービスへ接続する共通処理であったり、プログラムでビジネスロジックを記述する必要がある処理に関しては、Pythonを書いてこのAirflow上で動かすことができます。 3年ほど前にこのAirflowを本番環境で導入し、今では100件以上のワークフローを動かす基盤として運用しています。
BigQueryを中心としたETL基盤
BigQueryは、とにかく大量のデータを蓄積することが可能なので、Google Cloudに連携したデータのほとんどをここにロードしています。BigQueryに蓄積したデータを加工して、集計・分析用のデータマートを作成する、ELT(Extract, Load, Transform)の構成を取っています。データの加工には、SQLやJavaScript(BigQuery SQLのUDFとして利用)を主な手段として採用しています。BigQuery上のSQLであれば当然リソースはBigQueryのリソースを利用できるので、大量データを効率良く処理ができます。導入前はオンプレミス環境に構築したETLツールを用いて、サーバのリソースを割いてデータ加工の処理をしていましたが、BigQueryの導入によって、数億件のデータでも安定して高速で処理ができるようになりました。
BigQuery上のデータは、マーケターやエンジニア等のデータ利用者がSQLを実行して参照したり、Looker Studio、Googleスプレッドシート等を用いたレポートを作成して閲覧できるようにしています。 また、BigQueryのデータは集計データを蓄積するのみにとどまりません。後述するGoogle Cloud上に構築した業務Webアプリケーションが利用するCloud SQLやFirestoreに連携したり、BigQueryのリソースを用いて大量データを集計した結果を、AWSやSalesforce等の社内の別システムへの連携をしたりと、大量データを処理する業務システムとしての役割も担っています。
Looker StudioやGoogleスプレッドシートを用いたデータの活用
弊社ではエンジニア組織のみならず、全社的にグループウェアとしてGoogle Workspaceを利用しています。そのため、GoogleスプレッドシートやLooker StudioといったGoogleのサービスを用いることで、Googleアカウントとデータの閲覧権限があれば、URL一つで誰もが必要なデータにアクセスできる環境を目指しています。
Looker Studioでは、次の図のような図表やフィルタを簡単に作成して共有ができます。日々の業務で観測したいデータをまとめたダッシュボードを作成して、事業の意思決定に役立てています。参照するデータは前述のBigQuery上のデータを用いています。BigQueryやSQLの知識がなくても、GUI上で見たい指標を選んでグラフを作成したり、簡単な数式も組んだりすることができるので、データエンジニアに依存することなく、データの利用者がダッシュボードを編集できるようになりました。
Googleスプレッドシートにもまた、BigQueryに接続できるコネクタがあります。Looker Studioのようなダッシュボードではなく、慣れ親しんだ表計算を用いて集計業務をしたいケースに応えるために利用しています。従来はExcel上でマクロを組んで、複数のデータソースをまとめて処理していた業務を、BigQueryとスプレッドシートに置き換えることで、ある程度の業務の自動化が可能となりました。
また、集計や分析に必要なデータは、データ基盤に蓄積したデータのみではありません。集計したい指標の軸となる独自のマスタデータを管理して、それをBigQueryに連携するインターフェースとしてもGoogleスプレッドシートを利用しています。Googleスプレッドシートはデータ利用の入出力のインターフェースとして欠かせないものとなっています。
Cloud SQLやFirestoreを用いた業務アプリケーション
BigQueryは大量データを処理したり、集計したデータを一括で閲覧したりするのに向いている一方で、RDBMSのように業務アプリケーションで用いるデータベースとしては、パフォーマンスやコストの観点で非常に不向きです。Google Cloud上にためたデータをWebアプリケーション上で活用したいといったケースにも対応する場合は、Cloud SQLやFirestoreといった別のデータストアサービスも利用しています。
Cloud SQLは、RDBMSを利用できるマネージドサービスで、蓄積したデータをWebアプリケーション上で閲覧したり編集したりするために用いています。Webアプリケーションは同じくGoogle Cloud上のApp Engineで構築しています。BigQueryは、Cloud SQLへの接続設定をすることで、BigQuery上のデータとCloud SQL上のデータをSQLで結合して利用することもできるので非常に使い勝手が良いです。
Firestoreは、構成が複雑な構造化データをシステム化するために用いたNoSQLのデータストアです。RDBMSで表現がしにくい構造のデータ、項目数が多かったりばらつきがあったりして定義が難しいデータ等を用いたアプリケーション用に利用しています。
今後の課題
さて、今回ご紹介したデータ基盤ですが、今はデータの活用を推進していくフェーズとなっております。ビジネス上の課題を解決するためにデータ基盤を利用したり、○○のデータを集計したいといった話は多数いただきます。一方でデータの利用用途が部署ごとにバラバラで、結局は集計したいデータを一元で管理できていなかったり、あるいは既存のETLツールで組んだデータ連携処理+Excel上での集計処理から抜け出すことができなかったりと課題は多数あります。 データを活用する基盤がある今、更なる活用に向けて、私達データエンジニアも事業の理解と、データ活用の推進により力を入れていく必要があると感じています。
おわりに
本記事ではエス・エム・エスのキャリア事業におけるデータ基盤についての事例をご紹介しました。 私達のデータ基盤は、ご紹介した通りGoogle Cloudの技術をフルに活用しています。パブリッククラウドの知識やデータサイエンスの知識も勿論求められますが、ある程度の基盤が開発され、実際のデータの活用を推進していくフェーズの今、データを利用する人たちの課題を理解する力、そしてどういったデータを用いれば課題解決に繋がるのかを提案できる力も必要となっています。
エス・エム・エスは新しいメンバーを募集しています。
私達のチームは、筆者のようなデータエンジニアから、元は基幹アプリケーションの開発に携わっていたエンジニア、データやドメイン知識が豊富なプロダクトオーナーなど、様々なスキルセットを持ったメンバーで構成されています。データ活用を推進するBPR推進部として一丸となって日々の業務の課題の理解と解決に取り組んでいます。
弊社の事業に携わってみたい方、興味のある方は、ぜひこちらのページものぞいてみてください。